This feature is not yet available in
workflow-py. See our
Roadmap for feature parity plans and
Changelog for updates.
GitHub Repository
You can find the project source code which uses real APIs on Github.
- Build resilient AI applications with automatic retries
- Manage AI operations with workflow steps
- Implement tools and function calling with durability
- Handle errors gracefully across your AI operations
- Handle long-running AI operations with extended timeouts
Prerequisites
Before getting started, make sure you have:- An OpenAI API key
- Basic familiarity with Upstash Workflow and Vercel AI SDK
- Vercel AI SDK version 4.0.12 or higher (required for ToolExecutionError handling)
Installation
Install the required packages:Implementation
Creating OpenAI client
AI SDKs (Vercel AI SDK, OpenAI SDK etc.) uses the client’s default fetch implementation to make API requests, but allows you to provide a custom fetch implementation. In the case of Upstash Workflow, we need to use thecontext.call method to make HTTP requests. We can create a custom fetch implementation that uses context.call to make requests. By using context.call, Upstash Workflow is the one making the HTTP request and waiting for the response, even if it takes too long to receive response from the LLM.
The following code snippet can also be generalized to work with other LLM SDKs, such as Anthropic or Google.
Using OpenAI client to generate text
Now that we’ve created the OpenAI client, we can use it to generate the text. For that, we’re going to create a new workflow endpoint that uses the payload as prompt to generate text using the OpenAI client.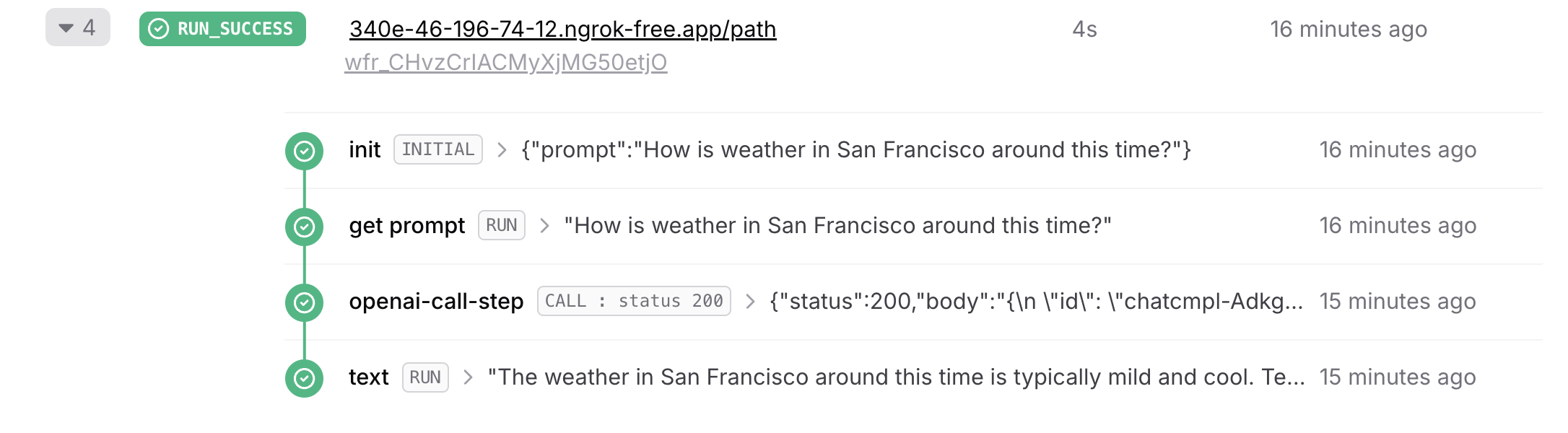
Advanced Implementation with Tools
Tools allow the AI model to perform specific actions during text generation. You can learn more about tools in the Vercel AI SDK documentation. When using tools with Upstash Workflow, each tool execution must be wrapped in a workflow step.The
maxSteps parameter must be greater than 1 when using tools to allow the model to process tool results and generate final responses. See the tool steps documentation for detailed explanation.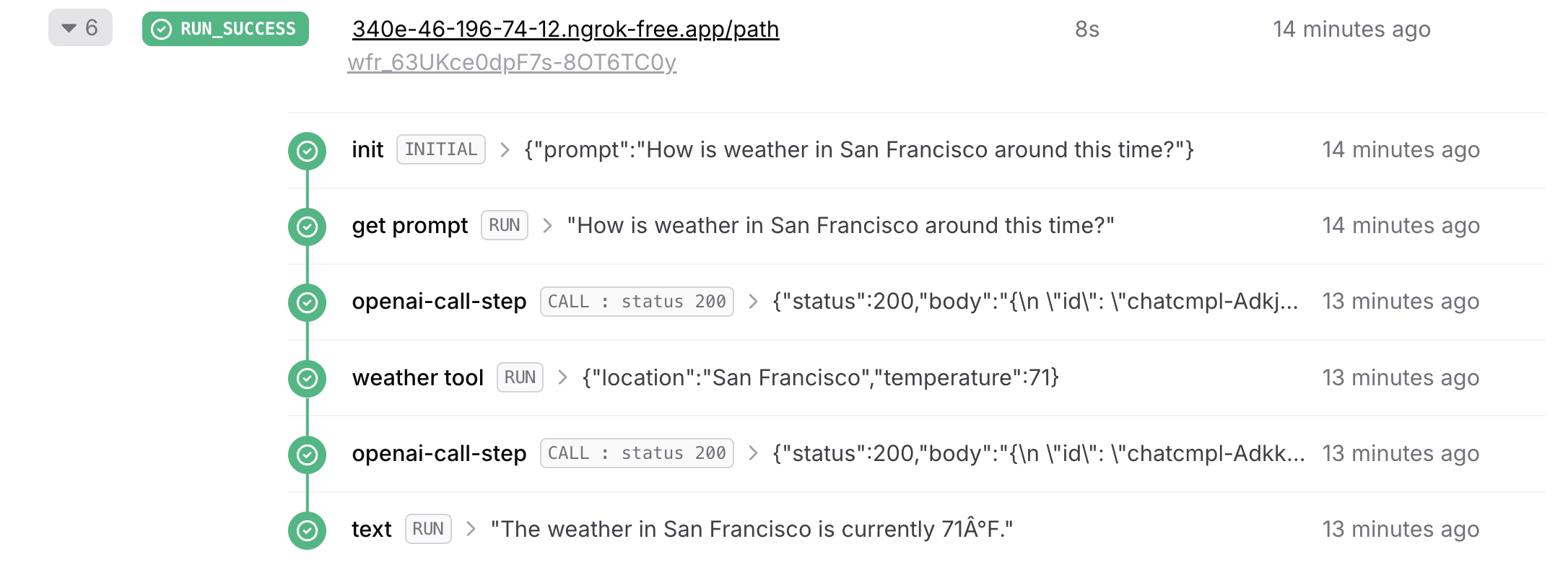
Important Considerations
When using Upstash Workflow with the Vercel AI SDK, there are several critical requirements that must be followed:Step Execution Order
The most critical requirement is thatgenerateText cannot be called before any workflow step. Always have a step before generateText. This could be a step which gets the prompt:
Error Handling Pattern
You must use the following error handling pattern exactly as shown. The conditions and their handling should not be modified:Tool Implementation
When implementing tools:- Each tool’s
executefunction must be wrapped in acontext.run()call - Tool steps should have descriptive names for tracking
- Tools must follow the same error handling pattern as above